I would like to elaborate this a bit more. Learning Artificial Neural Network (ANN) in two weeks has been tough. Prof. Ng’s Machine Learning course on Coursera explains the algorithm without getting into mathematical exposition or exposing the complexity behind the algorithms.
In the end, my perseverance paid off. I managed to complete the quizzes and the programming assignments. (It also meant, I had nearly locked myself indoors for two days revisiting the course lectures and notes.)
Didn’t ANN lose steam?
Actually it did. In fact, most of the AI based classification had shifted from ANN to support vector machines (SVM) or that’s what is written on Wikipedia. I do not know much about SVMs yet, although it wouldn’t be long before Prof. Ng explains it to me.
Here is an excellent concise history of ANN from Eric Robert’s Stanford archives. (Part 1: 1940-1980, Part 2: 1980-)
However, the real truth is that ANN has been rebranded as Deep Learning. Again, this is as per Wikipedia. I don’t know much about Deep Learning yet to comment on that. However, this prior knowledge will help me focus on the mechanisms of ANN later. Since I have the desire to explore TensorFlow, I would not want to skip or superficially skin through any important information.
How I untangled my own neural mess
As the lectures progressed, my understanding became more and more convoluted. By the time the lectures were over, my brain had completely fogged out.
I searched for some additional materials on the net and came across Andrej Karpathy’s (as of today) incomplete Hacker’s Guide to Neural Networks. Although most of the chapters aren’t written, the first chapter is excellent and gave me enough fodder to untangle the mess myself.

Well, this quote on Andrej’s guide also helped.
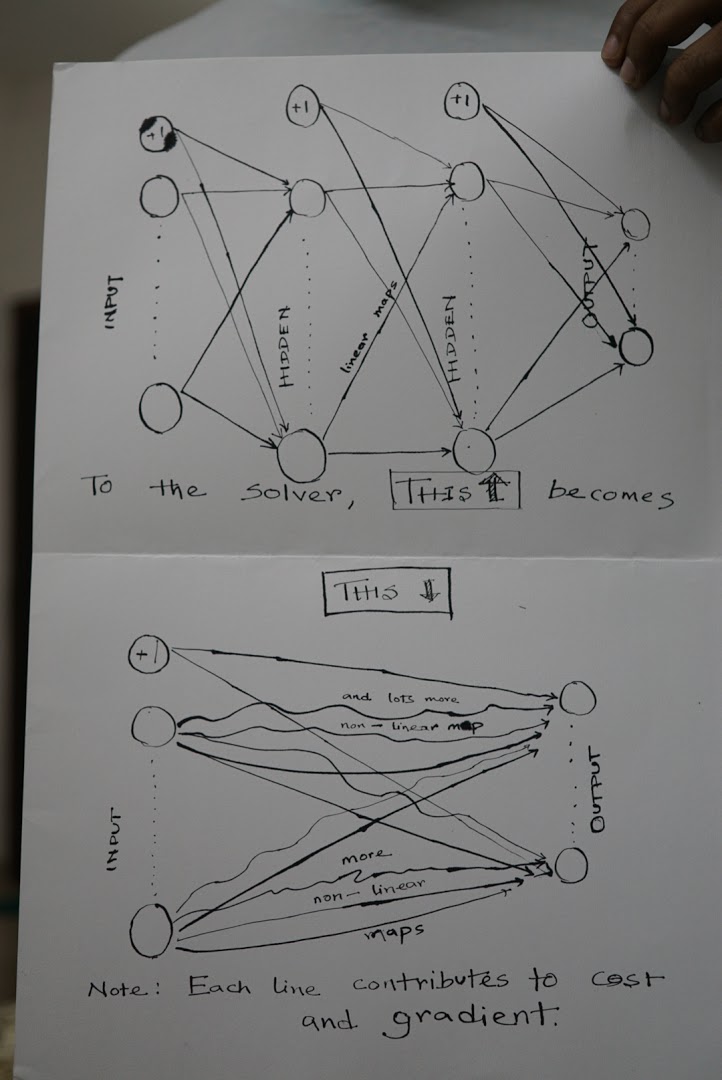
Ultimately, I realised that the approach taken to solve the problem is based on two principles already described in the first few lectures – that there is a cost function and there are all the gradient functions of that cost function. One uses whatever trick to find a point where the cost function is minimised. For that we have tons of minimisation functions like gradient descent or fminunc. This is no different from the basic regression and classification problems I had already studied.
The crucial step in understanding lies in the fact that there are tons of parameters that map the input to the output. Whatever is the case, one can always write output as a function of inputs and parameters. The backpropagation algorithm is nothing but a computation of all the gradient functions of the cost function with respect to each of the parameters.
In short, this is what happens –