
Previous Post: YetiDB: an academic exercise
We have a basic implementation of four interfaces—
- Record. This is the unit of data that can be written or retrieved. Since we are using protobufs, a protoc plugin
protoc-gen-go-yetigenerates the additional methods that will conform a protobuf to adhere to the Record interface. - Driver. A driver holds the connection to an underlying database engine. At present, it only supports local file system.
- Session. A session can run multiple transactions. At present it is only an abstraction layer to run managed transactions. Once we have a distributed architecture, having this abstraction would allow us to implement session-based consistency models.
- Transaction. A transaction can read or write Records, can be committed or rolled back.
The core idea is to have the interfaces defined and write a number of good test cases. This will help me when I get to serious implementations of db engines.
Implementation
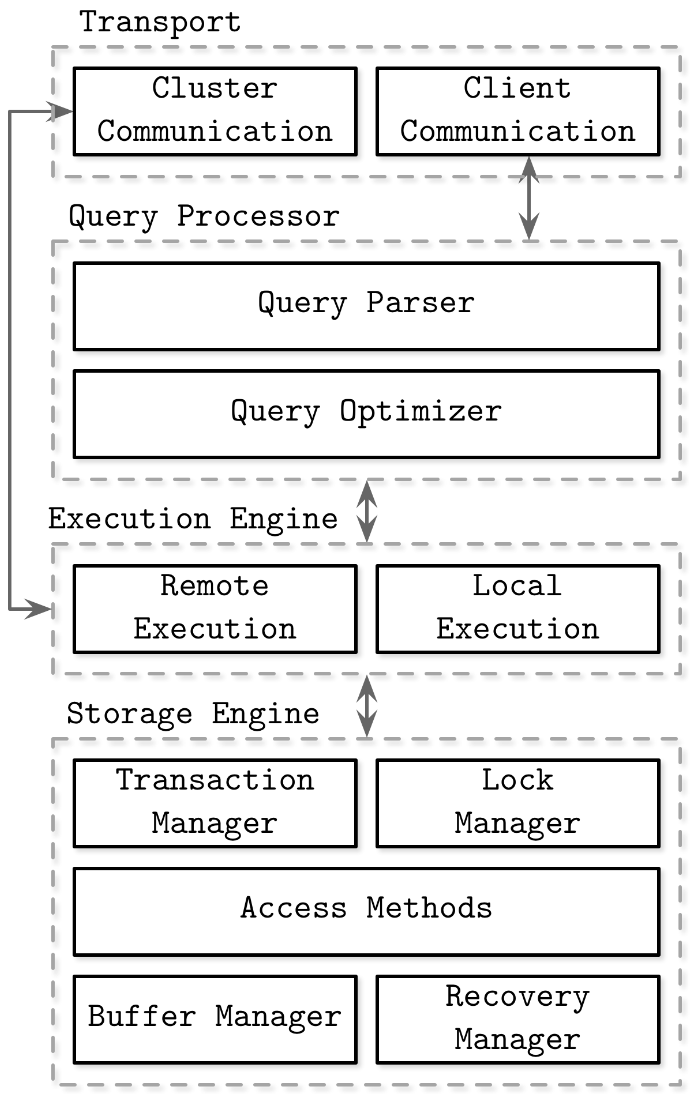
Ref: Database Internals by Alex Petrov
From an implementation standpoint, the Query Parser is rudimentary and the Query Optimizer is non existent. Sending a Record to the Write method analyses the underlying Type and constructs a unique filename based on the Primary Key. For reading data we have to send a Record to the Read method and it fetches all records that match the Type; in that sense, sending an empty Record to Read works as well. This is good enough for the skeletal implementation of a Query Processor.
Also, since the proof of concept is to work with human-readable files, the Storage Engine relies on transaction-based isolation, thereby allowing me to write a Transaction Manager and Access Methods the relies on common methods found in Go’s os package. I don’t need a Lock Manager as transactions happen in isolated folders. On top of it, file-based read and write locks are intrinsically taken care by os package. I have also decided to forego any implementation of Buffer Manager and Recovery Manager at this stage.
These files being local, the Transport section is not needed, as are any Remote Execution systems of the Execution Engine.
Isolation levels
The current file-based system implements a variation on read committed isolation level. Here is the definition from Database Internals—
… we can make sure that any read performed by the specific transaction can only read already committed changes. However, it is not guaranteed that if the transaction attempts to read the same data record once again at a later stage, it will see the same value. If there was a committed modification between two reads, two queries in the same transaction would yield different results. In other words, dirty reads are not permitted, but phantom and non-repeatable reads are. This isolation level is called read committed.
In addition to this, any write that is performed by the transaction, even-if the transaction is not committed, is read back.
State of code: https://github.com/sauvikbiswas/yeti/tree/74525383f909e6c6e710a8d57aac267acbb8f540